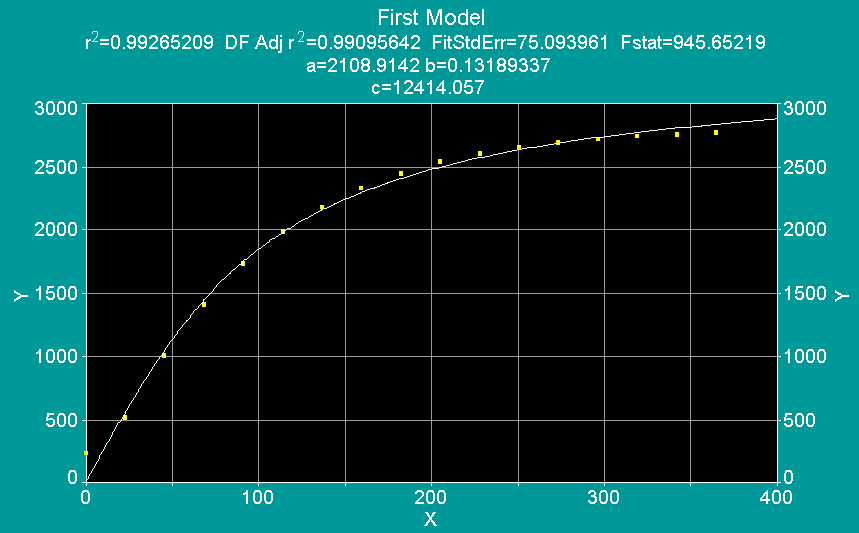
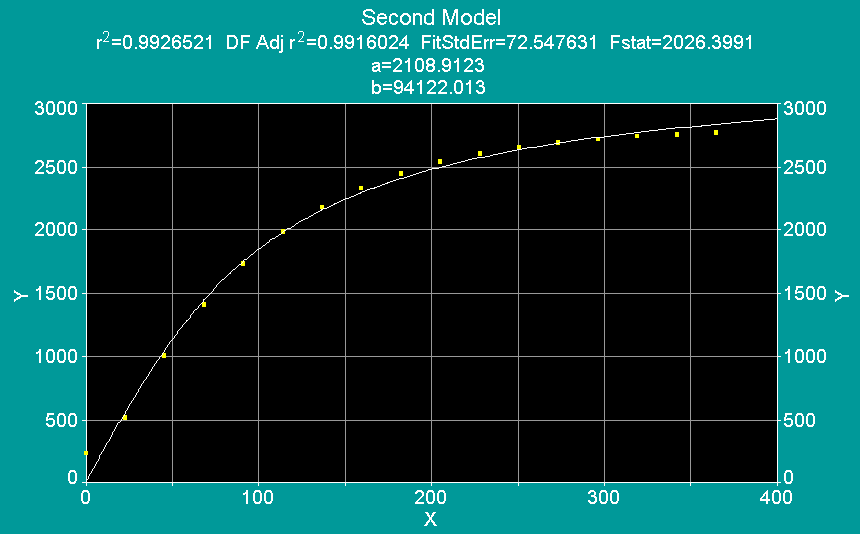
Compare that with the 7th order polynomial. Notice that the confidence intervals (and Standard Error) are very wide. The P-values for all of the parameters are all greater than .20, indicating that none of them are statistically significant to the model. In other words, they're not accurately describing the relationship between the equation and the data. However, notice that the r-squared value is higher.